![]()
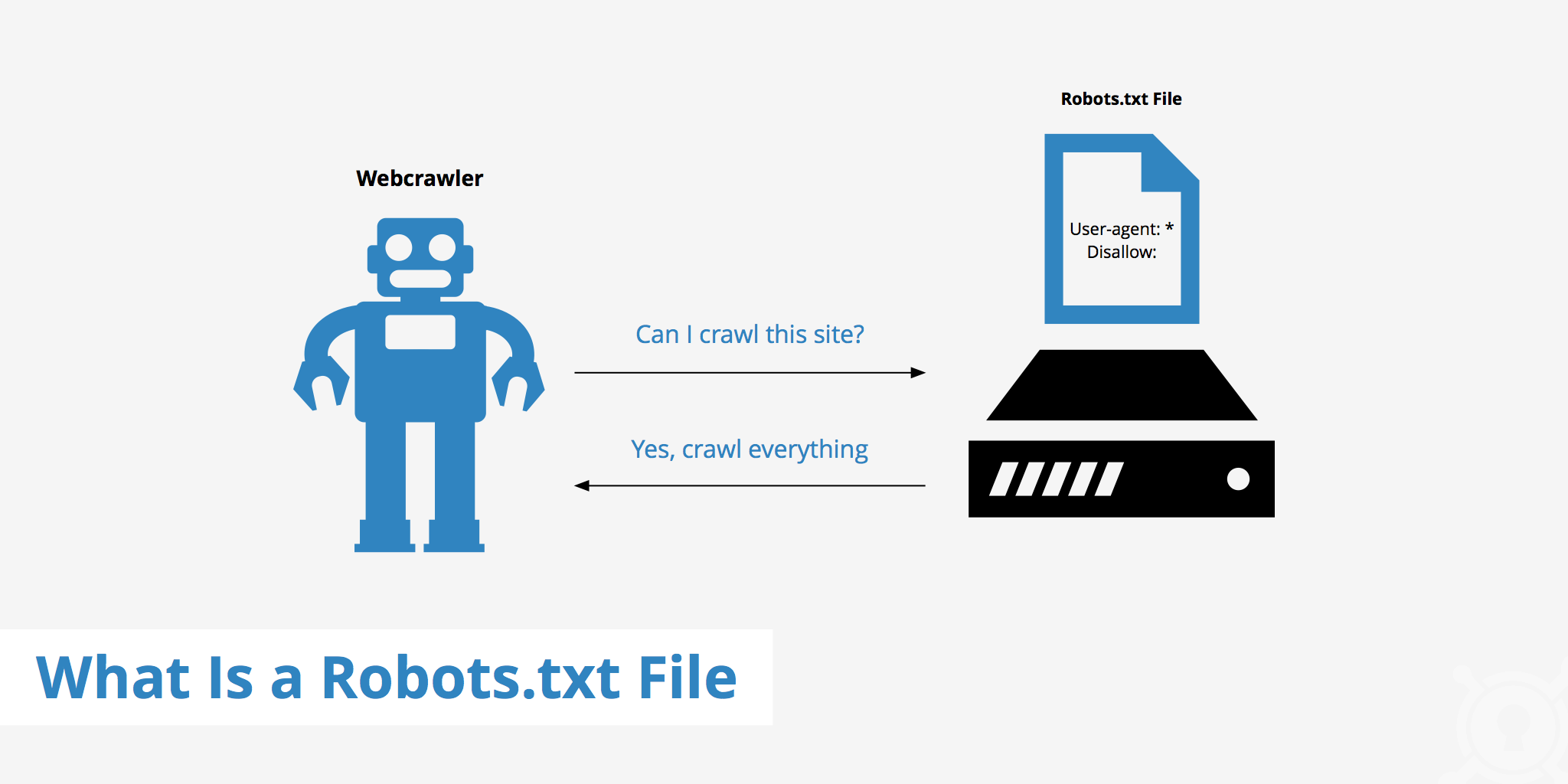
The Robots.txt File One way to begin understanding what’s running on a web server is to view the server’s robots.txt file. The robots.txt file is a listing of the directories and files on a web server that the owner wants web crawlers to omit from the indexing process. A web crawler is a piece of software that is used to catalog web information to be used in search engines and archives that are mostly commonly deployed by search engines such as Google and Yahoo. These web crawlers scour the internet and index (archive) all possible findings to improve the accuracy and speed of their internet search functionality.
To a hacker, the robots.txt file is a road map to identify sensitive information because any web server’s robots.txt file can be retrieved in a browser by simply requesting it in the URL. Here is an example robots.txt file that you can easily retrieve directly in your browser by simply requesting /robots.txt after a host URL.
# Notice: Crawling Facebook is prohibited unless you have express written
# permission. See: http://www.facebook.com/apps/site_scraping_tos_terms.php
User-agent: Applebot
Disallow: /ajax/
Disallow: /album.php
Disallow: /checkpoint/
Disallow: /contact_importer/
Disallow: /feeds/
Disallow: /file_download.php
Disallow: /hashtag/
Disallow: /l.php
Disallow: /live/
Disallow: /moments_app/
Disallow: /p.php
Disallow: /photo.php
Disallow: /photos.php
Disallow: /sharer/
User-agent: baiduspider
Disallow: /ajax/
Disallow: /album.php
Disallow: /checkpoint/
Disallow: /contact_importer/
Disallow: /feeds/
Disallow: /file_download.php
Disallow: /hashtag/
Disallow: /l.php
Disallow: /live/
Disallow: /moments_app/
Disallow: /p.php
Disallow: /photo.php
Disallow: /photos.php
Disallow: /sharer/
User-agent: Bingbot
Disallow: /ajax/
Disallow: /album.php
Disallow: /checkpoint/
Disallow: /contact_importer/
Disallow: /feeds/
Disallow: /file_download.php
Disallow: /hashtag/
Disallow: /l.php
Disallow: /live/
Disallow: /moments_app/
Disallow: /p.php
Disallow: /photo.php
Disallow: /photos.php
Disallow: /sharer/
User-agent: Googlebot
Disallow: /ajax/
Disallow: /album.php
Disallow: /checkpoint/
Disallow: /contact_importer/
Disallow: /feeds/
Disallow: /file_download.php
Disallow: /hashtag/
Disallow: /l.php
Disallow: /live/
Disallow: /moments_app/
Disallow: /p.php
Disallow: /photo.php
Disallow: /photos.php
Disallow: /sharer/
User-agent: ia_archiver
Disallow: /
Disallow: /ajax/
Disallow: /album.php
Disallow: /checkpoint/
Disallow: /contact_importer/
Disallow: /feeds/
Disallow: /file_download.php
Disallow: /hashtag/
Disallow: /l.php
Disallow: /live/
Disallow: /moments_app/
Disallow: /p.php
Disallow: /photo.php
Disallow: /photos.php
Disallow: /sharer/
User-agent: msnbot
Disallow: /ajax/
Disallow: /album.php
Disallow: /checkpoint/
Disallow: /contact_importer/
Disallow: /feeds/
Disallow: /file_download.php
Disallow: /hashtag/
Disallow: /l.php
Disallow: /live/
Disallow: /moments_app/
Disallow: /p.php
Disallow: /photo.php
Disallow: /photos.php
Disallow: /sharer/
User-agent: Naverbot
Disallow: /ajax/
Disallow: /album.php
Disallow: /checkpoint/
Disallow: /contact_importer/
Disallow: /feeds/
Disallow: /file_download.php
Disallow: /hashtag/
Disallow: /l.php
Disallow: /live/
Disallow: /moments_app/
Disallow: /p.php
Disallow: /photo.php
Disallow: /photos.php
Disallow: /sharer/
User-agent: seznambot
Disallow: /ajax/
Disallow: /album.php
Disallow: /checkpoint/
Disallow: /contact_importer/
Disallow: /feeds/
Disallow: /file_download.php
Disallow: /hashtag/
Disallow: /l.php
Disallow: /live/
Disallow: /moments_app/
Disallow: /p.php
Disallow: /photo.php
Disallow: /photos.php
Disallow: /sharer/
User-agent: Slurp
Disallow: /ajax/
Disallow: /album.php
Disallow: /checkpoint/
Disallow: /contact_importer/
Disallow: /feeds/
Disallow: /file_download.php
Disallow: /hashtag/
Disallow: /l.php
Disallow: /live/
Disallow: /moments_app/
Disallow: /p.php
Disallow: /photo.php
Disallow: /photos.php
Disallow: /sharer/
User-agent: teoma
Disallow: /ajax/
Disallow: /album.php
Disallow: /checkpoint/
Disallow: /contact_importer/
Disallow: /feeds/
Disallow: /file_download.php
Disallow: /hashtag/
Disallow: /l.php
Disallow: /live/
Disallow: /moments_app/
Disallow: /p.php
Disallow: /photo.php
Disallow: /photos.php
Disallow: /sharer/
User-agent: Twitterbot
Disallow: /ajax/
Disallow: /album.php
Disallow: /checkpoint/
Disallow: /contact_importer/
Disallow: /feeds/
Disallow: /file_download.php
Disallow: /hashtag/
Disallow: /l.php
Disallow: /live/
Disallow: /moments_app/
Disallow: /p.php
Disallow: /photo.php
Disallow: /photos.php
Disallow: /sharer/
User-agent: Yandex
Disallow: /ajax/
Disallow: /album.php
Disallow: /checkpoint/
Disallow: /contact_importer/
Disallow: /feeds/
Disallow: /file_download.php
Disallow: /hashtag/
Disallow: /l.php
Disallow: /live/
Disallow: /moments_app/
Disallow: /p.php
Disallow: /photo.php
Disallow: /photos.php
Disallow: /sharer/
User-agent: Yeti
Disallow: /ajax/
Disallow: /album.php
Disallow: /checkpoint/
Disallow: /contact_importer/
Disallow: /feeds/
Disallow: /file_download.php
Disallow: /hashtag/
Disallow: /l.php
Disallow: /live/
Disallow: /moments_app/
Disallow: /p.php
Disallow: /photo.php
Disallow: /photos.php
Disallow: /sharer/
User-agent: Applebot
Allow: /ajax/pagelet/generic.php/PagePostsSectionPagelet
Allow: /safetycheck/
User-agent: baiduspider
Allow: /ajax/pagelet/generic.php/PagePostsSectionPagelet
Allow: /safetycheck/
User-agent: Bingbot
Allow: /ajax/pagelet/generic.php/PagePostsSectionPagelet
Allow: /safetycheck/
User-agent: Googlebot
Allow: /ajax/pagelet/generic.php/PagePostsSectionPagelet
Allow: /safetycheck/
User-agent: ia_archiver
Allow: /about/privacy
Allow: /ajax/pagelet/generic.php/PagePostsSectionPagelet
Allow: /full_data_use_policy
Allow: /legal/terms
Allow: /policy.php
Allow: /safetycheck/
User-agent: msnbot
Allow: /ajax/pagelet/generic.php/PagePostsSectionPagelet
Allow: /safetycheck/
User-agent: Naverbot
Allow: /ajax/pagelet/generic.php/PagePostsSectionPagelet
Allow: /safetycheck/
User-agent: seznambot
Allow: /ajax/pagelet/generic.php/PagePostsSectionPagelet
Allow: /safetycheck/
User-agent: Slurp
Allow: /ajax/pagelet/generic.php/PagePostsSectionPagelet
Allow: /safetycheck/
User-agent: teoma
Allow: /ajax/pagelet/generic.php/PagePostsSectionPagelet
Allow: /safetycheck/
User-agent: Twitterbot
Allow: /ajax/pagelet/generic.php/PagePostsSectionPagelet
Allow: /safetycheck/
User-agent: Yandex
Allow: /ajax/pagelet/generic.php/PagePostsSectionPagelet
Allow: /safetycheck/
User-agent: Yeti
Allow: /ajax/pagelet/generic.php/PagePostsSectionPagelet
Allow: /safetycheck/
User-agent: *
Disallow: /
This robots.txt file is broken out into different sections:
1. User-agent: Applebot2. User-agent: baiduspider3. User-agent: Bingbot4. User-agent: Googlebot5. User-agent: ia_archiver6. User-agent: msnbot7. User-agent: Naverbot8. User-agent: seznambot9. User-agent: Slurp10.User-agent: teoma11.User-agent: Twitterbot12.User-agent: Yandex13.User-agent: Yeti14.User-agent: Applebot15.User-agent: baiduspider16.User-agent: Bingbot17.User-agent: Googlebot18.User-agent: ia_archiver19.User-agent: msnbot20.User-agent: Naverbot21.User-agent: seznambot22.User-agent: Slurp23.User-agent: teoma24.User-agent: Twitterbot25.User-agent: Yandex26.User-agent: Yeti
# Notice: Crawling Facebook is prohibited unless you have express written
# permission. See: http://www.facebook.com/apps/site_scraping_tos_terms.php
Clean URLs are absolute URL paths that you could copy and paste into your browser. Paths with no clean URLs are using a parameter, q in this example, to drive the functionality of the page. You may have heard this referred to as a builder page, where one page is used to retrieve data based solely on the URL parameter(s) that were passed in Directories and files are straightforward and self-explanatory.
Every web server must have a robots.txt file in its root directory otherwise web crawlers may actually index the entire site, including database, files, and all! Those are items no web server administrator wants as part of your next Google search. The root directory of a web server is the actual physical directory on the host computer where the web server software in installed. In windows,
the root directory is usually C:/inetpub/wwwroot/, and in Linux it’s usually a close variant of /var/www/. There is nothing stopping you from creating a web crawler of your own that provides the complete opposite functionality. Such a tool would, if you so desired, only request and retrieve items that appear in the robots.txt and would save you substantial time if you are performing recon on multiple web servers. Otherwise, you can manually request a review each robots.txt file in the browser. The robots.txt file is complete roadblock for automated web crawlers, but not even a speed bump for human hackers who want to review this sensitive information.
ALL THE INFORMATION USED HERE IN WWW.techietalks.online WEBSITE IS ONLY FOR EDUCATION AND AWARENESS PURPOSES NOTHING IS MEANT TO DO WITH UNETHICAL ACTIVITIES.
JOSH PAULI
SCOTT WHITE, TECHNICAL EDITOR
THE BASICS OF WEB HACKING

![Bykea Had Publicly Exposed 400+ Million Users Data Including [CNIC, Address, License] ETC](https://www.techietalks.online/wp-content/uploads/2021/02/Bykea-Data-Breached.png)

