
Luckily for us, Google provides “directives” that are easy to user and help us get the most out of every search. These directives are keywords that enable us to more accurately extract information from the Google index.
Consider the following example: assume you are looking for information on (TechyTalk) website (techietalks.online) about me. The simplest way to perform this search is to enter the following terms in a Google search box: Jahanzaib khan techytalk. This search will yield a fair number of hits. However (at the time of this writing), only four of the first 10 websites returned were pulled directly from the TechyTalk website.
By utilizing Google directives, we can force the Google index to do our bidding in the example above; we know both the target website and the keywords we want to search. More specifically, we are interested in forcing Google to return only results that are pulled directly from the target (techietalks.online) domain. In this case, our best choice is to utilize the “site:” directive. Using the “site:” directive directly from the specific website.
To properly use a Google directive you need three things:
- The name of the directive you want to use
- A colon
- The term you want to use in the directive
After you have entered the three pieces of information above, you can search as you normally would. To utilize the “site:” directive, we need to enter the following into a Google search box:
Site:domain term(s) to search
Note that there is no space between the directive, colon, and domain. In our earlier example, we wanted to conduct a search for Jahanzaib Khan on the techyTalk website. To accomplish this, we would enter the following command into the Google search bar:
site:techietalks.online jahanzaib khan
Running this search provides us with drastically different results than our initial attempt. First, we have trimmed the overall number of hits from 12,000+ down to more manageable 155. There is little doubt that a person can sort through and gather information from 155 hits much quicker than 12,000. Seconds and possibly more importantly, every single returned result comes directly from the target website. Utilizing the “site:” directive is a great way to search a specific target and look for additional information. This directive allows you to avoid search overlaod and to focus your search.
ALERT!
It is worth nothing that all searches in Google are case insensitive so “jahanzaib”, “Jahanzaib”, and “JAHANZAIB” will all return the same results!
Another good Google directive to use is “intitle:” or “allintitle:” Adding either of these to your search causes only websites that have you search words in the Title of the web paste to be returned. The difference between “intitle:” and “allintitle:” is straightforward. “allintitle:” will only return website that contain all the keywords in the web page title. The “intitle:” directive will return any page whose title contains at least one of the keywords you entered.
A classic example of putting the “allintitle:” Google hack to work is to perform the following search:
Allintitle:index of
Performing this search will allow us to view a list of any directories that have been indexed and are available via the web server. This is often a great place to gather reconnaissance on your target.
If we want to search for sites that contain specific words in the URL, we can use the “inurl:” directive. For example, we can issue the following command to locate potentially interesting pages on our target’s web page:
Inurl:admin
This search can be extremely useful in revealing administrative or configuration pages on your target’s website.
It can also be very valuable to search the Google cache rather than the target’s website. This process not only reduces your digital Footprinting on the target’s server, making it harder to catch you, it also provides a hacker with the occasional opportunity to view web pages and files that have been removed from the original website. The Google cache contains a stripped-down copy of each website that the Google bots have spidered and cataloged. It is important to understand that the cache contains both the code used to build the site and many of the files that were discovered during the spidering process. These files can be portable document formats (PDFs), MS Office documents like Word and Excel, text files, and more.
It is not uncommon today for information to be placed on the internet by mistake. Consider the following example. Suppose you are network administrator for a company. You use MS Excel to create a simple workbook containing all the IP addresses, computer names, and locations of the personal computers (PCs) in your network. Rather than carrying this Excel spreadsheet around, you decide to publish it to your company’s intranet where it will be accessible only by people within your organization. However, rather than publishing this document to the intranet website, you mistakenly publish it to the computer internet website. If the Google bots spider your site before you take this file down, it is possible that the document will live on in the Google cache even after you have removed it from your site. As a result, it is important to search the Google cache too.
We can use the cache: directive to limit our search results and how only the information pulled directly from the Google cache. The following search will provide us with the cached version of the TechyTalk Homepage:
Cache:techietalks.online
It is important that you understand that clicking on any of the URLs will bring you to the live website, not the cached version. If you want to view specific cached pages, you will need to modify your search.
The last directive we will cover here is “filetype:”. We can utilize “filetype:” to search for specific file extensions. This is extremely useful for finding specific types of files on your target’s website. For example, to return only this that contain PDF documents , you would issue the following command:
Filetype:pdf
This powerful directive is a great way to find links to specific files like .doc, xlsx, ppt, txt, and many more. Your options are nearly limitless.
For additional flexibility, we can combine multiple directives into the same search. For example, if we want to find all the PowerPoint presentations on the DSU website, you would enter the following command into the search box:
site:techietalks.online filetype:pdf
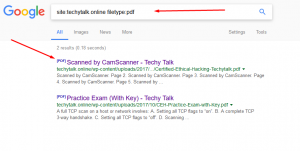
In this case, every result that is returned is a PDF file and comes directly from the techietalks.online website domain. Check out the above screenshot. The first utilized Google directives and the second show the result from a traditional search.
Oftentimes, Google Hacking can also be referred to as “Google Dorks”. When an application has a specific vulnerability, hacker and security researchers will typically place a Google Dork in the exploit, which allow you to search for vulnerable versions utilizing Google. The exploit-db.com website which is run by the folks who created BackTrack and Kali Linux (Offensive Security) has an extensive list of Google Dorks and additional Google Hacking Techniques. If you visit http://www.exploit-db.com and go to the Google Hacking Database (GHDB) link.
You can select what to look for and use the large repository within the exploit-db.com website to help aid you in your target.
Some other ones that often have a high yield of success with Google are the Following:
- Inurl:login (or the following):
- Logon
- Signin
- Signon
- Forgotpassword
- Forgot
- Reset
ALL THE INFORMATION REGARDING GOOGLE DIRECTIVES OR SO CALLED GOOGLE DORKS ARE ONLY FOR SECURITY RESEARCHERS AND ETHICAL HACKERS AND MOST IMPORTANTLY FOR THE STUDENTS AWARNESS AND ALSO FOR THOSE WHO WANT TO LEARN AND BEGIN CAREER AS AN ETHICAL HACKER. SO THE INFORMATION USED HERE IN WWW.techietalks.online IS ONLY FOR EDUCATION AND AWARNESS PURPOSES THERE IS NOTHING BLACK HAT HACKING TAUGHT OR SUPPORTED. THE INFORMATION I GATHERED FROM THE BOOK OF “THE BASCIS OF HACKING AND PENETRATION TESTING BY PATRICK ENGEBRETSON”.

![Bykea Had Publicly Exposed 400+ Million Users Data Including [CNIC, Address, License] ETC](https://www.techietalks.online/wp-content/uploads/2021/02/Bykea-Data-Breached.png)


Thanks for this great article .
Thanks for this great article .
Thank you very much! Really appreciate this.
This is one of the most comprehensive posts! Thanks
I really love it.
Thank you very much! Really appreciate this.
This is one of the most comprehensive posts! Thanks
This is really great stuff. Thanks again.
Thank you very much! Really appreciate this.
I really love it.
I really love it.
This really helps me a lot. Thanks!
This really helps me a lot. Thanks!
Thanks a lot.
I really love it.
Thank you very much! Really appreciate this.
Thanks a lot.
Thanks a lot.
This really helps me a lot. Thanks!
This is really great stuff. Thanks again.
This really helps me a lot. Thanks!
This is one of the most comprehensive posts! Thanks
Thanks a lot.
This really helps me a lot. Thanks!
I really love it.
Thanks a lot.
Thanks for the free guide, the pictures really help to figure out what you’re supposed to be doing. Cheers!
Thank you very much! Really appreciate this.
Thanks for this great article .
I really love it.
I really love it.
Thank you very much! Really appreciate this.
This really helps me a lot. Thanks!
I really love it.
Thank you very much! Really appreciate this.
Thank you very much! Really appreciate this.
This really helps me a lot. Thanks!
Thanks a lot.
Very nice and easy to follow article. Thanks!
I think other web-site proprietors should take this site as an model, very clean and excellent user genial style and design, let alone the content. You are an expert in this topic!
Hello to all, the contents present at this web site are genuinely amazing for people knowledge, well, keep up the good work fellows.
Hi there, this weekend is good in favor of me, for the reason that this point in time i am reading this wonderful educational paragraph here at my home.